How Do I Perform Chi-Square Tests in Excel Using SigmaXL?
Chi-Square Test & Association
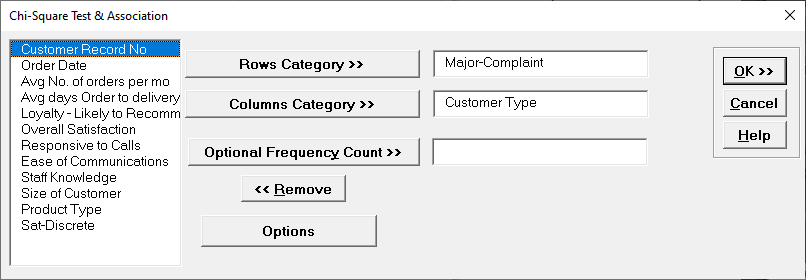
Open Customer Data.xlsx. Click Sheet 1 tab. The
discrete data of interest is Complaints and Customer Type, i.e., does the type of
complaint differ across customer type? Formally the Null Hypothesis is that there is no
relationship (or independence) between Customer Type and Complaints.
Click SigmaXL > Statistical Tools > Chi-Square Test &
Association.
Ensure that the entire data table is selected. If not, check Use Entire Data
Table. Click Next.
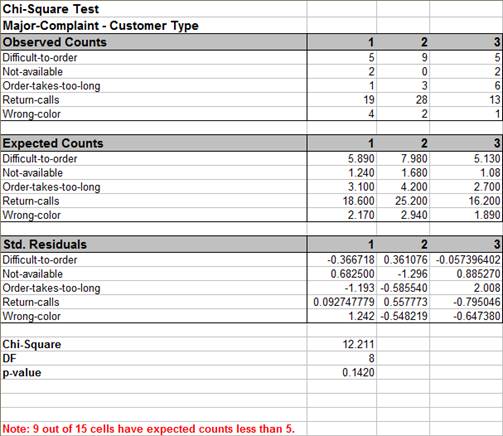
With the p-value = 0.142 we fail to reject H0, so we do not have enough evidence to show
a difference in customer complaints across customer types.
Note: 9 out of 15 cells have expected counts less than 5. If more than
20% of the cells have expected counts less than 5 (or if any of the cells have an
expected count less than 1), the Chi-Square approximation may be invalid. Use Chi-Square
Test Fishers Exact.
Tip: Use Advanced Pareto Analysis and Excel's 100% Stacked Column Chart
to complement Chi-Square Analysis.
Caution: When using stacked column format data with Ordinal
Category variables that are text, SigmaXL will sort alphanumerically which may not
result in the correct ascending order for analysis. We recommend coding text Ordinal
variables as numeric (e.g., 1,2,3) or modified text (e.g., Sat_0, Sat_1).
Press F3 or click Recall SigmaXL Dialog to recall last
dialog.
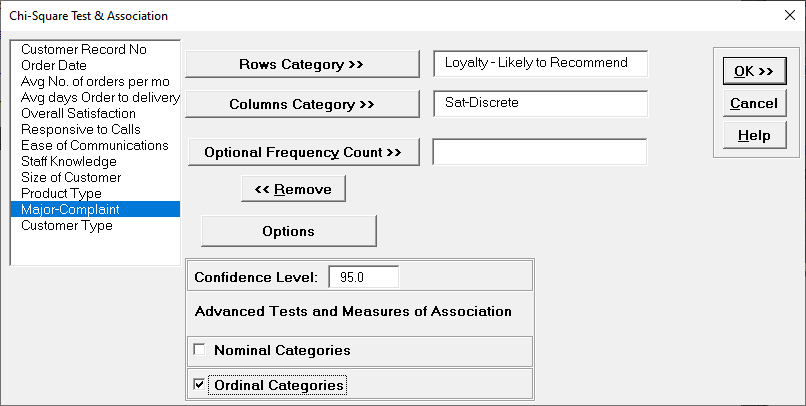
Select Loyalty Likely to Recommend, click Rows Category
>>; select Sat-Discrete, click Columns Category
>>.
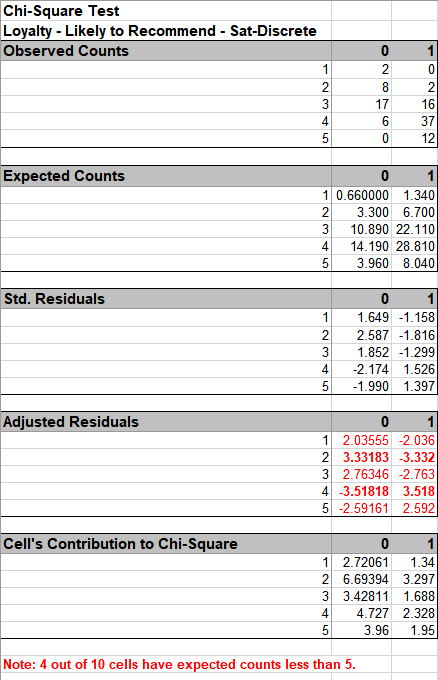
Click Options, check Ordinal Categories.
Sat-Discrete is derived from Overall Satisfaction where a score >= 3.5 is
considered a 1, and scores < 3.5 are considered a 0.
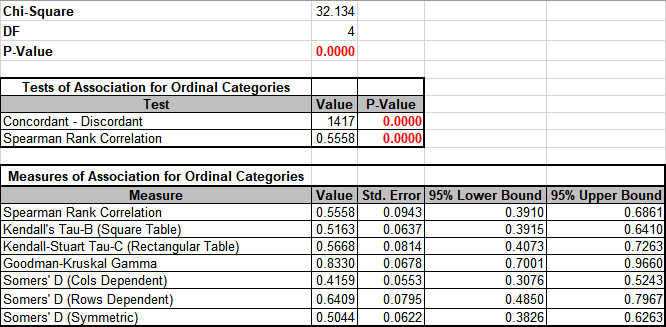
Click OK. Results:
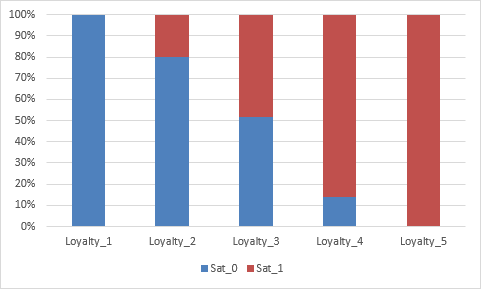
As expected, there is a strong positive association between Loyalty and Discrete
Satisfaction.
Note: Kendall-Stuart Tau-C should be used here rather than Tau-B because it is a
rectangular table.
Since Satisfaction leads to Loyalty, Loyalty is the Dependent variable, so Rows
Dependent Somer's D should be used rather than Cols Dependent or Symmetric.
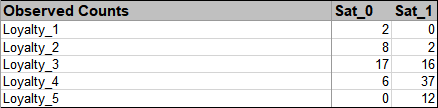
In order to visualize the row and column percentages with Excel's 100% Stacked Column
Chart, we will need to modify the numeric row and column labels as shown, converting to
text as shown:
Select cells A3:C8 of the Chi-Square sheet.
Click Excel's Insert > Insert Column or Bar Chart
and select 100% Stacked Column as shown.
Click to create the 100% stacked column chart (uncheck the Chart Title):
Chi-Square Test (Two-Way Table Data)
Open the file Attribute Data.xlsx, ensure that Example
1 Sheet is active.
This data is in Two Way Table format, or pivot table format.
Note that cells B2:D4 have been pre-selected.
Click SigmaXL > Statistical Tools > Chi-Square Test & Association
Two-Way Table Data.
Note the selection of data includes the Row and Column labels (if we had Row and Column
Totals these would NOT be selected).
Do not check Advanced Tests and Measures of Association.
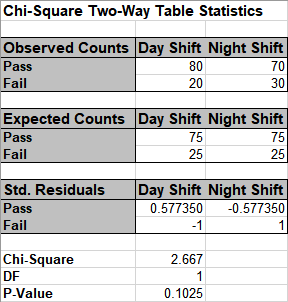
The p-value matches that of the 2 proportion test. Since the p-value of 0.1 is greater
than .05, we fail to reject H0.
Now click Example 2 Sheet tab.
The Yields have not changed but we have doubled the sample size.
Repeat the above analysis.
The resulting output is:
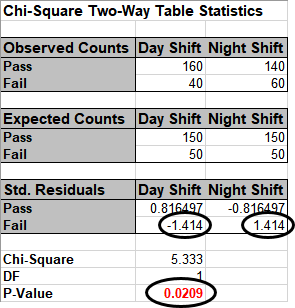
Since the p-value is < .05, we now reject the Null Hypothesis, and conclude that Day
Shift and Night Shift are significantly different.
The Residuals tell us that Day Shift failures are less than expected (assuming equal
proportions), and Night Shift failures are more than expected.
Note, by doubling the sample size, we improved the power or sensitivity of the test.
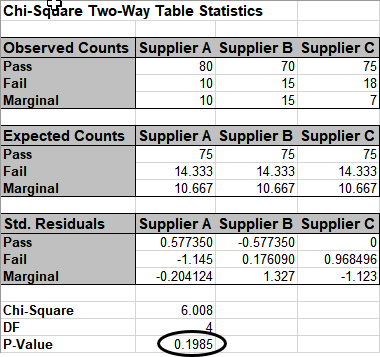
Click the Example 3 Sheet tab.
In this scenario we have 3 suppliers, and an additional marginal level. A random sample
of 100 units per supplier is tested. The null hypothesis here is: No relationship
between Suppliers and Pass/Fail/Marginal rates, but in this case we can state it as No
difference across suppliers.
Redoing the above analysis (for selection B2:E5) yields the following:
The p-value tells us that we do not have enough evidence to show that there is a
difference across the 3 suppliers.
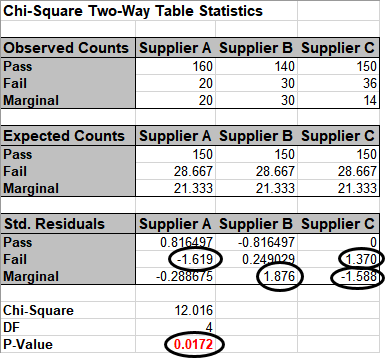
Click the Example 4 Sheet tab.
Here we have doubled the sample size to 200 per supplier.
Note that the percentages are identical to example 3.
Redoing the above analysis yields the following:
With the P-Value < .05 we now conclude that there is a significant difference across
suppliers.
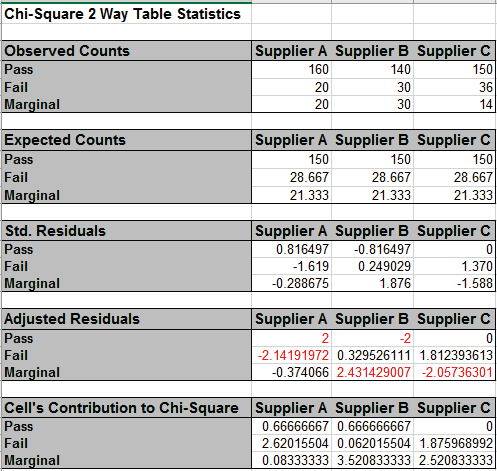
Examining the Std. (Standardized) Residuals tells us that Supplier A has fewer failures
than expected (if there was no difference across suppliers), Supplier B has more
marginal parts than expected and Supplier C has fewer marginal parts than expected.
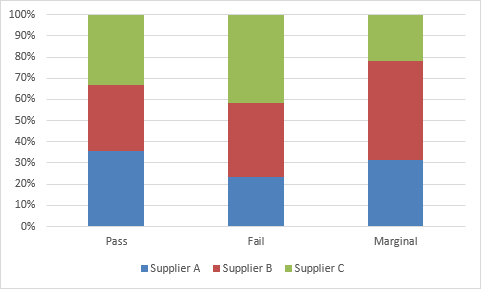
The table row and column cell percentages can be visualized using Excel's 100% Stacked
Column Chart.
Select cells A3:D6 of the Chi-Square sheet.
Click Excel's Insert > Insert Column or Bar Chart
and select 100% Stacked Column as shown.
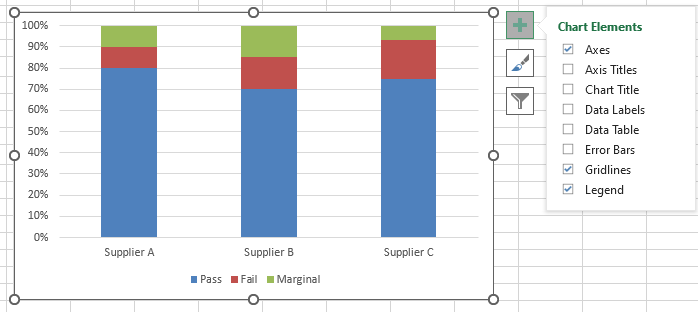
Click to create the 100% stacked column chart. Uncheck the Chart Title as shown.
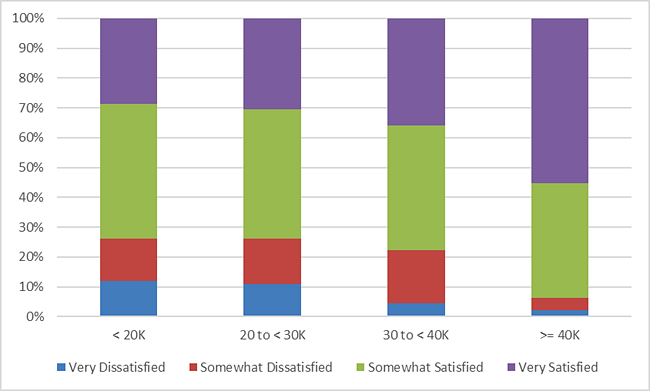
The rows and columns can easily be switched by clicking Design >
Switch Row/Column.
These charts make it easy to visualize the cell row and column percentages.
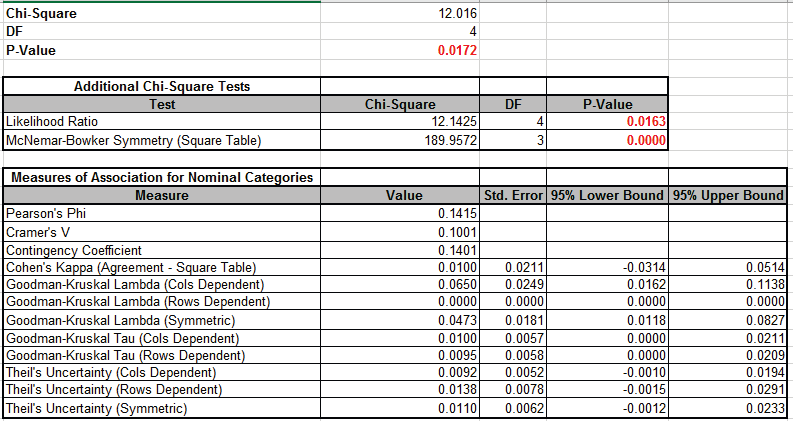
Chi-Square Test Two-Way Table Data: Advanced Tests and Measures of Association Nominal
Categories
Checking the Nominal Categories option provides additional chi-square statistics and measures
of association, including:
Adjusted Residuals
Equivalent to normal z score
Red font highlight denotes significant cell residual value
Bold red highlight denotes significant cell residual value with Bonferroni
adjustment
Note: red highlight is only active if Chi-Square P-Value is significant
Cells Contribution to Chi-Square
Additional Chi-Square Tests
Likelihood Ratio
McNemar-Bowker Symmetry (Square Table)
For a 2x2 table, McNemar's test is equivalent to a paired two-proportions test,
for example applicable to studying before versus after change in proportion on
the same subject.
The returned P-Value is exact, based on the binomial distribution.
Bowker extended McNemar's test for square tables larger than 2x2.
The null hypothesis is that the table is symmetrical (i.e., symmetry of
disagreement).
This uses Chi-Square as the test statistic.
Measures of Association for Nominal Categories
Pearson's Phi
Pearson's Phi is equivalent to Pearson's correlation coefficient for a 2x2
table.
It is the most popular measure of association for 2x2 tables.
We recommend the following rules-of-thumb, adapted from Cohen (1988):
< 0.1 = Very Weak
0.1 to < 0.3: Weak (Small Effect)
0.3 to < 0.5: Moderate (Medium Effect)
> 0.5: Strong (Large Effect)
Although Phi is equivalent to Pearson's correlation for a 2x2 table, we
recommend these rules-of-thumb for use in typical contingency tables, rather
than those commonly used for correlation (i.e., > 0.9 = Strong).
Cramer's V
Cramer's V is an extension of Phi for larger tables. It is the most popular
measure of association for tables of any size.
It varies from 0 to 1, with 0 = no association and 1 = perfect association.
Use Cohen's rules-of-thumb given above for Phi.
Contingency Coefficient
An alternative to Phi, varies from 0 to < 1.
Use Cohen's rules-of-thumb given above for Phi.
Cohen's Kappa (Agreement - Square Table)
Kappa is used to measure agreement between two assessors evaluating the same
parts or items.
For an extended Attribute Measurement Systems Analysis use SigmaXL >
Measurement Systems Analysis > Attribute MSA.
For Attribute MSA used in Six Sigma quality, the recommendation is Kappa
> 0.9 is strong agreement and < 0.7 is weak agreement, but for general
use, the less stringent guidelines by Fleiss are recommended:
Kappa: >= 0.75 or so signifies excellent agreement, for most purposes,
and <= 0.40 or so signifies poor agreement.
Goodman-Kruskal Lambda & Tau and Theil's Uncertainty
Measures of Proportional Reduction in Predictive Error.
The basic concept is a measure that indicates how much knowing the value of the
independent variable improves our ability to estimate the value of the dependent
variable.
They are Directional Measures. If the Y dependent variable is in the
Rows Category, then use the Rows Dependent measure. If
the Y dependent variable is in the Columns Category, then use
the Cols Dependent measure.
If there is no clear X-Y dependent-independent relationship, then use the
Symmetric measures (not available for Tau).
Use Cohen's rules-of-thumb for these measures.
See Appendix Chi-Square Tests and (Contingency) Table
Associations for further formula details and references. The following are external
links with helpful presentations on measures of association for contingency tables:
https://course1.winona.edu/bdeppa/STAT%20701%20Online/stat_701%20home.htm Click
4a) Measures of Association.
This is a narrated presentation, but a regular PowerPoint is also available on the web
site.
It is part of a Biostatistics course by Dr. Brant Deppa, Department of Mathematics and
Statistics, Winona State University.
Press F3 or click Recall SigmaXL Dialog to recall last
dialog. Check Nominal Categories as shown:
Click Next. The resulting output is:
The adjusted residuals are equivalent to normal z values, so for a specified 95%
confidence level, any value greater than 1.96 (or less than -1.96) is highlighted in
red.
This results in a slight difference in interpretation from that of the standardized
residuals, but the 3 largest magnitude residuals are consistent.
As noted above, the Chi-Square P-Value tells us that there is a significant difference
across suppliers, in other words, there is association between Supplier and
Pass/Fail/Marginal, but it does not tell us the degree or strength of that association.
Cramer's V is used for tables larger than 2x2 and from the rules-of-thumb, the 0.1 value
is considered weak (or small effect).
Computing Odds Ratio and Confidence Interval for 2x2 Table
Odds Ratio and Confidence Intervals are not directly available for 2x2 Tables but can
obtained using Logistic Regression.
The table data must be rearranged to stacked column format and the response changed to
Event/Trial format.
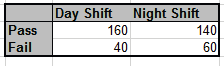
Example 2 of Attribute Data.xlsx:
would be changed to:
Note, coding Shift as continuous numeric is easier to interpret and is valid because it has
a range of 1.
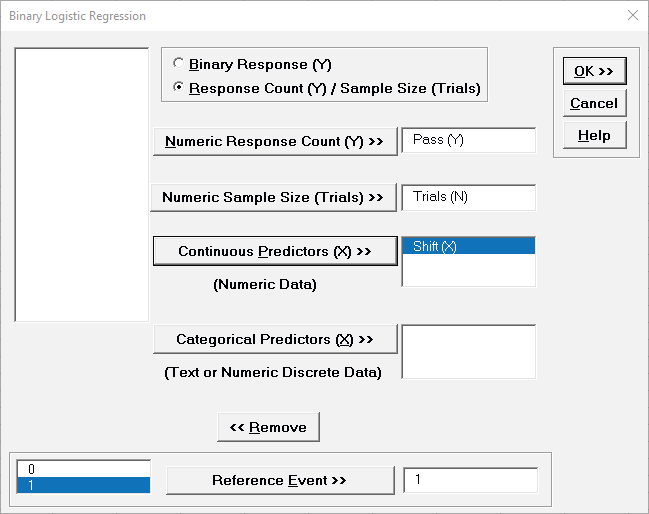
Analyze using SigmaXL > Statistical Tools > Regression > Binary Logistic
Regression.
Select Response Count (Y) / Sample Size. Pass(Y) is selected as
Numeric Response Count (Y), Trials (N) is Numeric Sample
Size (Trials) and Shift (X) is selected as Continuous
Predictors (X):
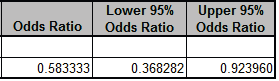
Click OK. The Odds Ratio and Confidence Limits are given as:
The shift change 1 to 2 is 0.583 times as likely to produce passed (good) product with a 95%
confidence interval of 0.368 to 0.924.
Chi-Square Test Two-Way Table Data: Advanced Tests and Measures of Association Ordinal
Categories
Checking the Ordinal Categories option provides statistics and measures of
association appropriate when both row and column category variables are ordinal:
Adjusted Residuals and Cells Contribution to Chi-Square
Tests of Association for Ordinal Categories
Concordant Discordant
The P-Value for this hypothesis test is from Kendall's Tau-B, but is the
same for all of the Concordant Discordant ordinal measures:
Tau-C, Gamma and Somer's D. See Agresti (2010).
This may differ from other software using an approximation formula.
Spearman Rank Correlation
Measures of Association for Ordinal Categories with Confidence Intervals
Use Tau-B for square tables (no. rows = no. columns) and Tau-C for
rectangular tables (no. rows <> no. columns).
Tau-B, Tau-C and Gamma are asymmetric measures, so will give the same result
regardless of variable assignment to Rows and Columns.
These are all Concordant Discordant measures.
Somers' D (Cols & Rows Dependent, Symmetric)
Also a Concordant Discordant measure but directional. If the Y dependent
variable is in the Rows Category, then use the Rows Dependent measure.
If the Y dependent variable is in the Columns Category, then use the Cols
Dependent measure.
If there is no clear X-Y dependent-independent relationship, then use the
Symmetric measure.
SigmaXL provides rules-of-thumb for Kendall's Correlation in Ordinal Attribute MSA
(strong association is > 0.8) and Pearson or Spearman Correlation (strong
association is > 0.9), however these are in the context of measurement systems
analysis, design of experiments or a controlled process study.
For typical contingency table applications, we recommend the rules-of-thumb, adapted
from Cohen (1988):
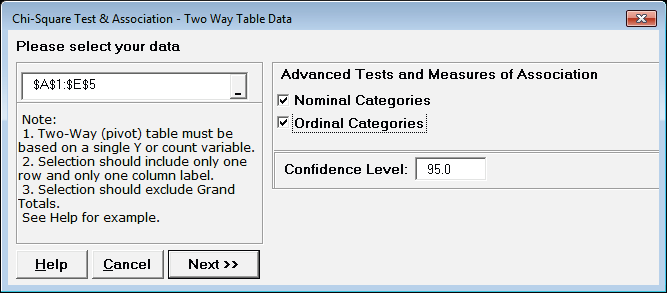
Open the file Attribute Data.xlsx, click Example 5 Salary Sat Sheet tab.
This data is in two-way table format and has ordinal categories: Salary in the Rows and Satisfaction Level in the Columns.
Note that cells A1:E5 have been pre-selected.
Click SigmaXL > Statistical Tools > Chi-Square Tests > Chi-Square Test & Association Two-Way Table Data. Note the selection of data includes the Row and Column labels (if we had Row and Column Totals these would NOT be selected).
Check Nominal Categories and Ordinal Categories as shown:
Tip: Even if the categories are ordinal, it is sometimes useful to select nominal categories as well for comparison purposes.
Click Next. The resulting output is:
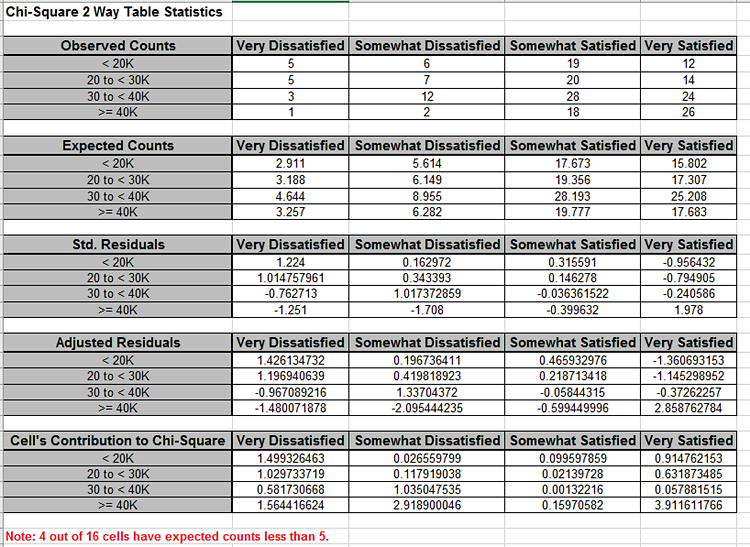
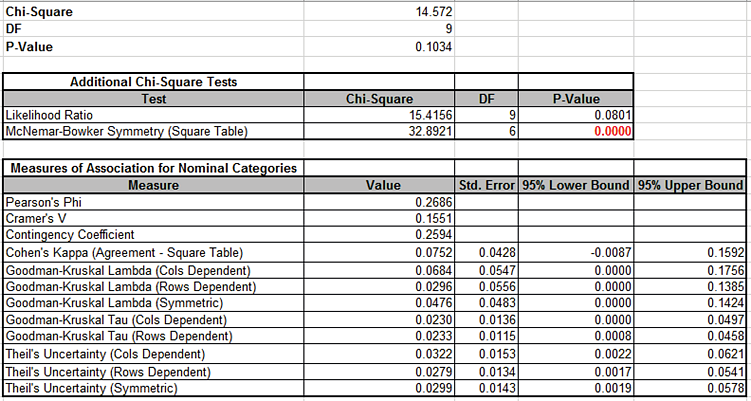
Note that the Chi-Square P-Value is 0.1, indicating that there is no significant association between
Salary and Satisfaction when they are treated as nominal categories (although the significant result for McNemar-Bowker does show that there is
lack of symmetry in the off diagonals).
Since the Chi-Square P-Value is not significant, the Adjusted Residuals are not highlighted, even though some values are greater than 1.96 (and less than -1.96).
This follows the concept used in ANOVA called Fisher Protected where one considers the significance of post-hoc tests only when the overall test is significant.
Note: 4 out of 16 cells have expected counts less than 5.
If more than 20% of the cells have expected counts less than 5 (or if any of the cells have an expected count less than 1), the Chi-Square approximation may be invalid, and Fishers Exact should be used.
This will be discussed later, but for this example the Fishers Monte-Carlo Exact P-Value = 0.095 so does not change the interpretation of the results for the above Chi-Square analysis.
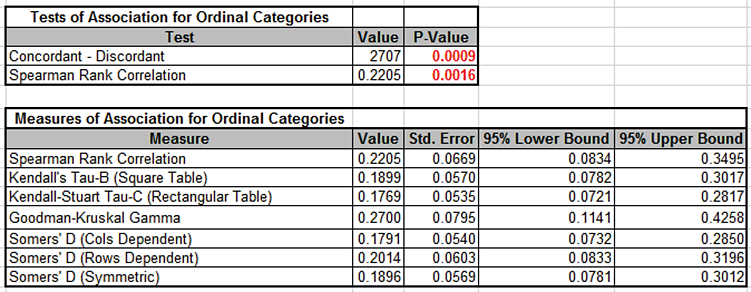
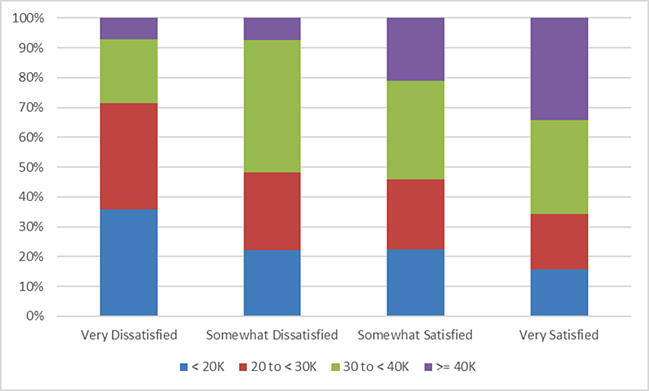
When Salary and Satisfaction are treated as ordinal categories, the more powerful Concordant Discordant and Spearman Rank Correlation
P-Values clearly show that there is a significant association.
The Measures of Association for Ordinal Categories show that this is positive, i.e., an increase in Salary is associated with an increase in Satisfaction.
However, using the rules-of-thumb given above, we see that the association is weak.
The table row and column cell percentages can be visualized using Excel's 100% Stacked Column Chart.
Select cells A3:E7 of the Chi-Square sheet.
Click Excel's Insert > Insert Column or Bar Chart and select 100% Stacked Column as shown.
Click to create the 100% stacked column chart (uncheck the Chart Title):
The rows and columns can easily be switched by clicking Design > Switch Row/Column